Saron Samuel, Dan DeGenaro, Jimena Guallar-Blasco, Kate Sanders, Oluwaseun Eisape, Arun Reddy, Alexander Martin, Andrew Yates, Eugene Yang, Cameron Carpenter, David Etter, Efsun Kayi, Matthew Wiesner, Kenton Murray, and Reno Kriz
Video-ColBERT: Contextualized Late Interaction for Text-to-Video Retrieval
Arun Reddy*, Alexander Martin*, Eugene Yang, Andrew Yates, Kate Sanders, Kenton Murray, Reno Kriz, Celso M Melo, Benjamin Van Durme, and Rama Chellappa
In IEEE Conference on Computer Vision and Pattern Recognition, Jun 2025
In this work, we tackle the problem of text-to-video re- trieval (T2VR). Inspired by the success of late interaction techniques in text-document, text-image, and text-video re- trieval, our approach, Video-ColBERT, introduces a simple and efficient mechanism for fine-grained similarity assess- ment between queries and videos. Video-ColBERT is built upon three main components: a fine-grained spatial and temporal token-wise interaction, query and visual expan- sions, and a dual sigmoid loss during training. We find that this interaction and training paradigm leads to strong in- dividual, yet compatible representations for encoding video content. These representations lead to increases in perfor- mance on common text-to-video retrieval benchmarks com- pared to other bi-encoder methods.
MultiVENT 2.0: A Massive Multilingual Benchmark for Event-Centric Video Retrieval
Reno Kriz, Kate Sanders, David Etter, Kenton Murray, Cameron Carpenter, Kelly Van Ochten, Hannah Recknor, Jimena Guallar-Blasco, Alexander Martin, Ronald Colaianni, Nolan King, Eugene Yang, and Benjamin Van Durme
In IEEE Conference on Computer Vision and Pattern Recognition, Jun 2025
Efficiently retrieving and synthesizing information from large-scale multimodal collections has become a critical challenge. However, existing video retrieval datasets suffer from scope limitations, primarily focusing on matching descriptive but vague queries with small collections of professionally edited, English-centric videos. To address this gap, we introduce MultiVENT 2.0, a large-scale, multilingual event-centric video retrieval benchmark featuring a collection of more than 218,000 news videos and 3,906 queries targeting specific world events. These queries specifically target information found in the visual content, audio, embedded text, and text metadata of the videos, requiring systems leverage all these sources to succeed at the task. Preliminary results show that state-of-the-art vision-language models struggle significantly with this task, and while alternative approaches show promise, they are still insufficient to adequately address this problem. These findings underscore the need for more robust multimodal retrieval systems, as effective video retrieval is a crucial step towards multimodal content understanding and generation.
2024
Cross-Document Event-Keyed Summarization
William Walden, Pavlo Kuchmiichuk, Alexander Martin, Chihsheng Jin, Angela Cao, Claire Sun, Curisia Allen, and Aaron Steven White
Organizing perceived change into events is a key element of human cognition, and so to understand data as humans do, AI systems must model events of human interest. While natural language enables straightforward ways to represent complex events, visual data does not facilitate analogous methods and, consequently, introduces unique challenges in event understanding. To tackle complex event modeling in multimodal settings, we introduce a multimodal formulation for arbitrarily complex events and cast the extraction of these events as a three-stage span retrieval task. We propose a corresponding benchmark for this task, MultiVENT Grounded, that consists of 14.5 hours of densely annotated current event videos and 1,168 text documents, containing 22.8K labeled event-centric entities. We propose a collection of LLM-driven approaches to the task of multimodal event analysis, and evaluate both on MultiVENT Grounded. Results illustrate the challenges that abstract event understanding in noisy content poses while also demonstrating promise in event-centric video-language systems.
Hi5: 2D Hand Pose Estimation with Zero Human Annotation
Masum Hasan, Cengiz Ozel, Nina Long, Alexander Martin, Samuel Potter, Tariq Adnan, Sangwu Lee, Amir Zadeh, and Ehsan Hoque
We propose a new large synthetic hand pose estimation dataset, Hi5, and a novel inexpensive method for collecting high-quality synthetic data that requires no human annotation or validation. Leveraging recent advancements in computer graphics, high-fidelity 3D hand models with diverse genders and skin colors, and dynamic environments and camera movements, our data synthesis pipeline allows precise control over data diversity and representation, ensuring robust and fair model training. We generate a dataset with 583,000 images with accurate pose annotation using a single consumer PC that closely represents real-world variability. Pose estimation models trained with Hi5 perform competitively on real-hand benchmarks while surpassing models trained with real data when tested on occlusions and perturbations. Our experiments show promising results for synthetic data as a viable solution for data representation problems in real datasets. Overall, this paper provides a promising new approach to synthetic data creation and annotation that can reduce costs and increase the diversity and quality of data for hand pose estimation.
Event-Keyed Summarization
William Gantt, Alexander Martin, Pavlo Kuchmiichuk, and Aaron Steven White
In Conference on Empirical Methods in Natural Language Processing, Nov 2024
We introduce event-keyed summarization (EKS), a novel task that marries traditional summarization and document-level event extraction, with the goal of generating a contextualized summary for a specific event, given a document and an extracted event structure. We introduce a dataset for this task, MUCSUM, consisting of summaries of all events in the classic MUC-4 dataset, along with a set of baselines that comprises both pretrained LM standards in the summarization literature, as well as larger frontier models. We show that ablations that reduce EKS to traditional summarization or structure-to-text yield inferior summaries of target events and that MUCSUM is a robust benchmark for this task. Lastly, we conduct a human evaluation of both reference and model summaries, and provide some detailed analysis of the results.
FAMuS: Frames Across Multiple Sources
Siddharth Vashishtha, Alexander Martin, William Gantt, Benjamin Van Durme, and Aaron Steven White
In Conference of the North American Chapter of the Association for Computational Linguistics, Jun 2024
Understanding event descriptions is a central aspect of language processing, but current approaches focus overwhelmingly on single sentences or documents. Aggregating information about an event across documents can offer a much richer understanding. To this end, we present FAMuS, a new corpus of Wikipedia passages that report on some event, paired with underlying, genre-diverse (non-Wikipedia) source articles for the same event. Events and (cross-sentence) arguments in both report and source are annotated against FrameNet, providing broad coverage of different event types. We present results on two key event understanding tasks enabled by FAMuS: source validation—determining whether a document is a valid source for a target report event—and cross-document argument extraction—full-document argument extraction for a target event from both its report and the correct source article.
2023
MegaWika: Millions of reports and their sources across 50 diverse languages
Samuel Barham, Orion Weller, Michelle Yuan, Kenton Murray, Mahsa Yarmohammadi, Zhengping Jiang, Siddharth Vashishtha, Alexander Martin, Anqi Liu, Aaron Steven White, Jordan Boyd-Graber, and Benjamin Van Durme
To foster the development of new models for collaborative AI-assisted report generation, we introduce MegaWika, consisting of 13 million Wikipedia articles in 50 diverse languages, along with their 71 million referenced source materials. We process this dataset for a myriad of applications, going beyond the initial Wikipedia citation extraction and web scraping of content, including translating non-English articles for cross-lingual applications and providing FrameNet parses for automated semantic analysis. MegaWika is the largest resource for sentence-level report generation and the only report generation dataset that is multilingual. We manually analyze the quality of this resource through a semantically stratified sample. Finally, we provide baseline results and trained models for crucial steps in automated report generation: cross-lingual question answering and citation retrieval.
Jurassic World Remake: Bringing Ancient Fossils Back to Life via Zero-Shot Long Image-to-Image Translation
Alexander Martin, Haitian Zheng, Jie An, and Jiebo Luo
With a strong understanding of the target domain from natural language, we produce promising results in translating across large domain gaps and bringing skeletons back to life. In this work, we use text-guided latent diffusion models for zero-shot image-to-image translation (I2I) across large domain gaps (longI2I), where large amounts of new visual features and new geometry need to be generated to enter the target domain. Being able to perform translations across large domain gaps has a wide variety of real-world applications in criminology, astrology, environmental conservation, and paleontology. In this work, we introduce a new task Skull2Animal for translating between skulls and living animals. On this task, we find that unguided Generative Adversarial Networks (GANs) are not capable of translating across large domain gaps. Instead of these traditional I2I methods, we explore the use of guided diffusion and image editing models and provide a new benchmark model, Revive-2I, capable of performing zero-shot I2I via text-prompting latent diffusion models. We find that guidance is necessary for longI2I because, to bridge the large domain gap, prior knowledge about the target domain is needed. In addition, we find that prompting provides the best and most scalable information about the target domain as classifier-guided diffusion models require retraining for specific use cases and lack stronger constraints on the target domain because of the wide variety of images they are trained on.
A New Interpretation of Relative Importance on an Analysis of Per and Polyfluorinated Alkyl Substances (PFAS) Exposures on Bone Mineral Density
Andrea B. Kirk, Alisa DeStefano, Alexander Martin, Karli C. Kirk, and Clyde F. Martin
Background: The relative contribution of environmental contaminants is an important, and frequently unanswered, question in human or ecological risk assessments. This interpretation of relative importance allows determination of the overall effect of a set of variables relative to other variables on an adverse health outcome. There are no underlying assumptions of independence of variables. The tool developed and used here is specifically designed for studying the effects of mixtures of chemicals on a particular function of the human body. Methods: We apply the approach to estimate the contributions of total exposure to six PFAS (perfluorodecanoic acid, perfluorohexane sulfonic acid, 2-(N-methyl-PFOSA) acetate, perfluorononanoic acid, perfluoroundecanoic acid and perfluoroundecanoic acid) to loss of bone mineral density relative to other factors related to risk of osteoporosis and bone fracture, using data from subjects who participated in the US National Health Examination and Nutrition Surveys (NHANES) of 2013–2014. Results: PFAS exposures contribute to bone mineral density changes relative to the following variables: age, weight, height, vitamin D2 and D3, gender, race, sex hormone binding globulin, testosterone, and estradiol. Conclusion: We note significant alterations to bone mineral density among more highly exposed adults and significant differences in effects between men and women.
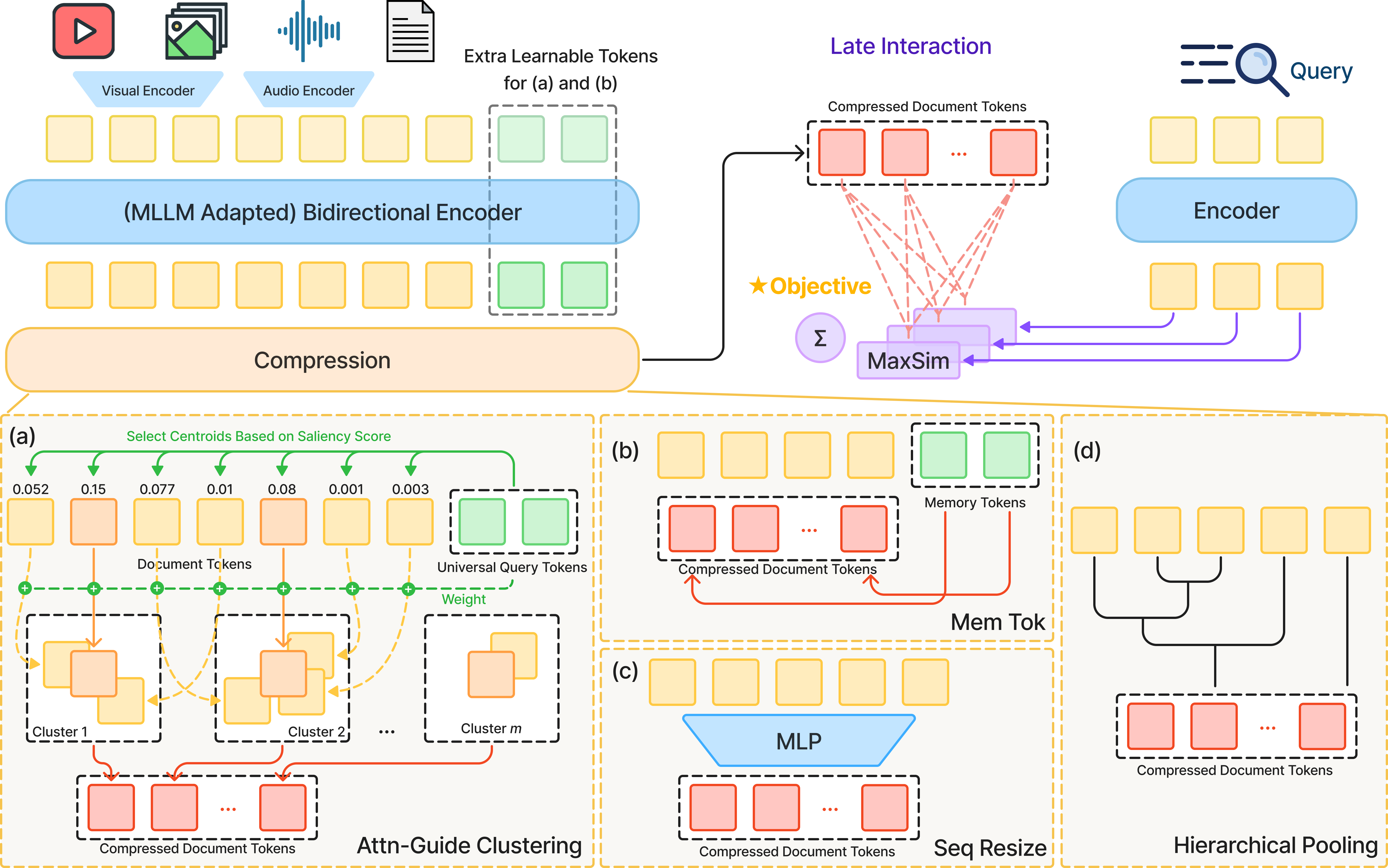 Multi-Vector Index Compression in Any Modality2026
Multi-Vector Index Compression in Any Modality2026 RANKVIDEO: Reasoning Reranking for Text-to-Video Retrieval2026
RANKVIDEO: Reasoning Reranking for Text-to-Video Retrieval2026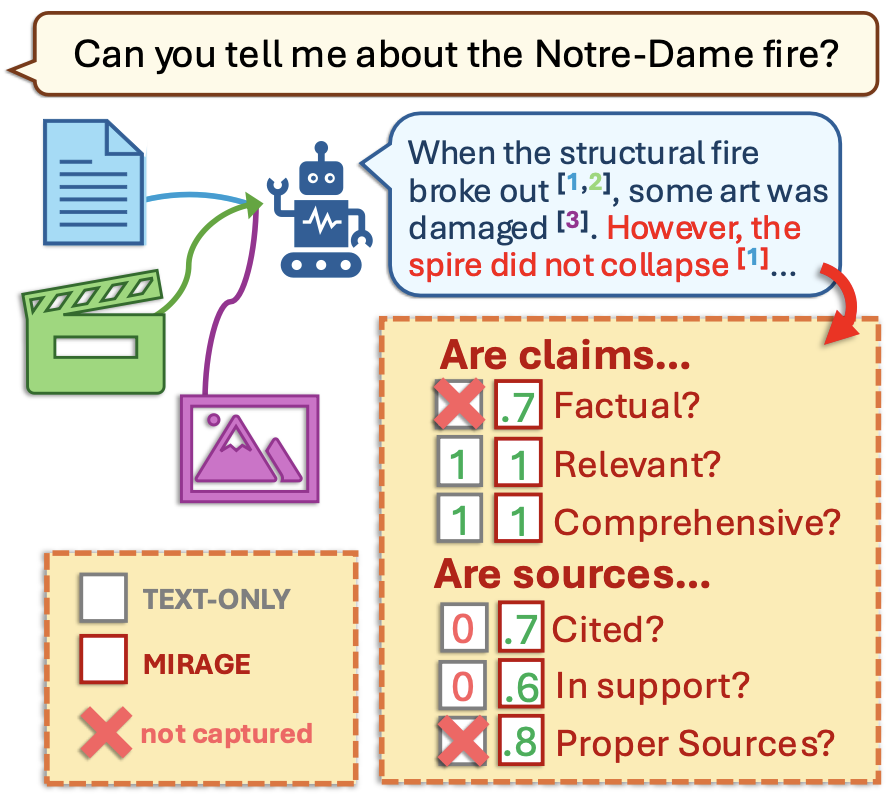 Seeing Through the MiRAGE: Evaluating Multimodal Retrieval Augmented Generation2025
Seeing Through the MiRAGE: Evaluating Multimodal Retrieval Augmented Generation2025










