Alexander Martin
Ph.D. Student at Johns Hopkins University

I am a Ph.D. student at Johns Hopkins University, advised by Dr. Ben Van Durme. My research focuses on multimodal retrieval and understanding, specifically advancing efficient and scalable search over large multimodal collections and end-to-end reasoning and synthesis over retrieved multimodal content.
My work spans:
- Efficient multimodal retrieval with late interaction models and multi-vector index compression.
- Complex and large scale retrieval over video collections in multilingual real-world settings and with complex user needs.
- Multimodal RAG and generation generating and grounding text in retrieved multimodal content, including mutli-video, cross-modal settings, and under uncertainty.
- Evaluation of retrieval, generation, and RAG systems, introducing metrics and interpreting relationships.
My keywords are: multimodal retrieval, search, video understanding, multimodal RAG, efficiency.
Before Johns Hopkins, I got my B.S. from the University of Rochester advised by Dr. Jiebo Luo and Dr. Aaron Steven White.
[Resume]
news
| Apr 28, 2026 | 1 paper accepted at SIGIR 2026! |
|---|---|
| Apr 27, 2026 | 1 paper accepted at ACL 2026! |
| Feb 26, 2025 | 2 for papers at CVPR 2025! |
| Aug 26, 2024 | Starting Ph.D. at JHU |
selected publications
-
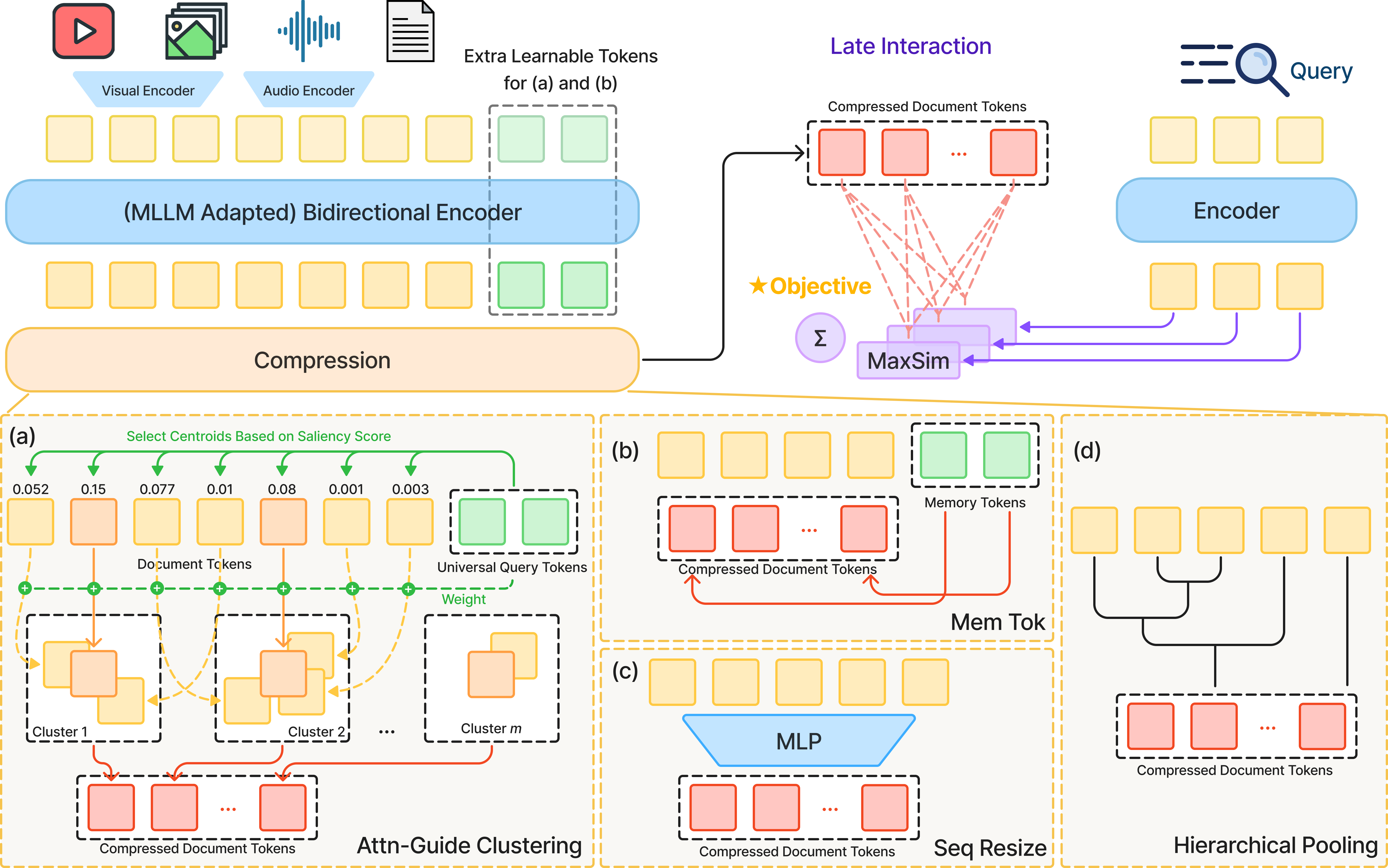 Multi-Vector Index Compression in Any Modality2026
Multi-Vector Index Compression in Any Modality2026 -
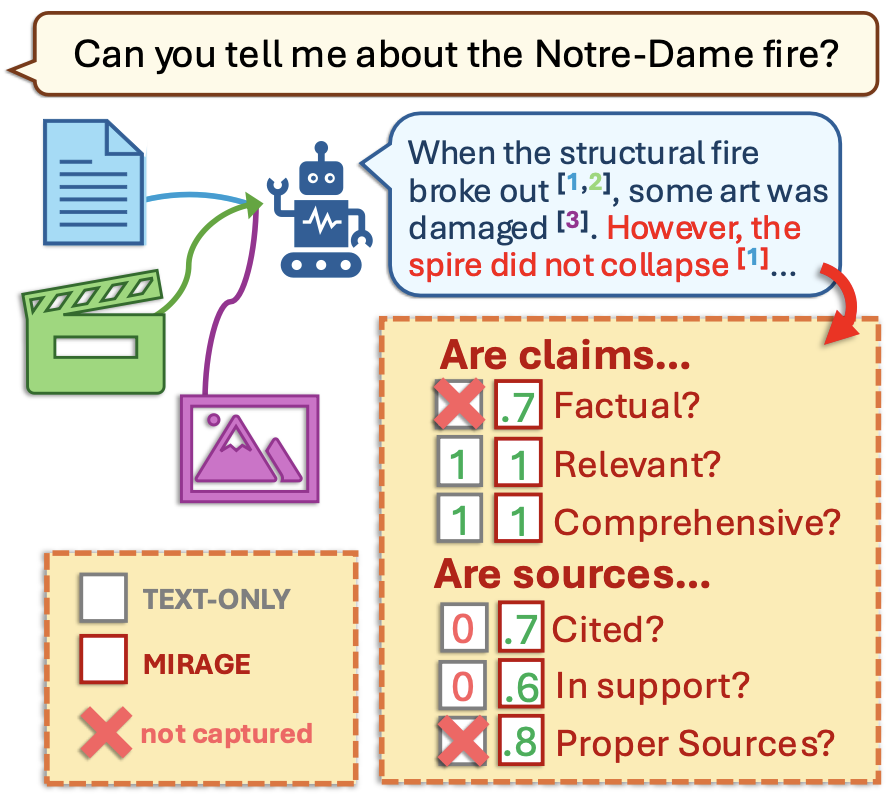 Seeing Through the MiRAGE: Evaluating Multimodal Retrieval Augmented Generation2025
Seeing Through the MiRAGE: Evaluating Multimodal Retrieval Augmented Generation2025 -




